Amazon Intern VO Round 1: Top X Most Frequent Tags Among Friends & Friends-of-Friends
This problem is from Amazon 2026 Intern Virtual Onsite Round 1. It tests the combined use of graph traversal (BFS), HashMap frequency counting, and Heap — a classic Top-K problem in a social network context.
Problem Description
Imagine you have a Twitter-style social network. Each user has a list of friends, and each user has posted some posts. Each post can carry multiple tags.
Your task:
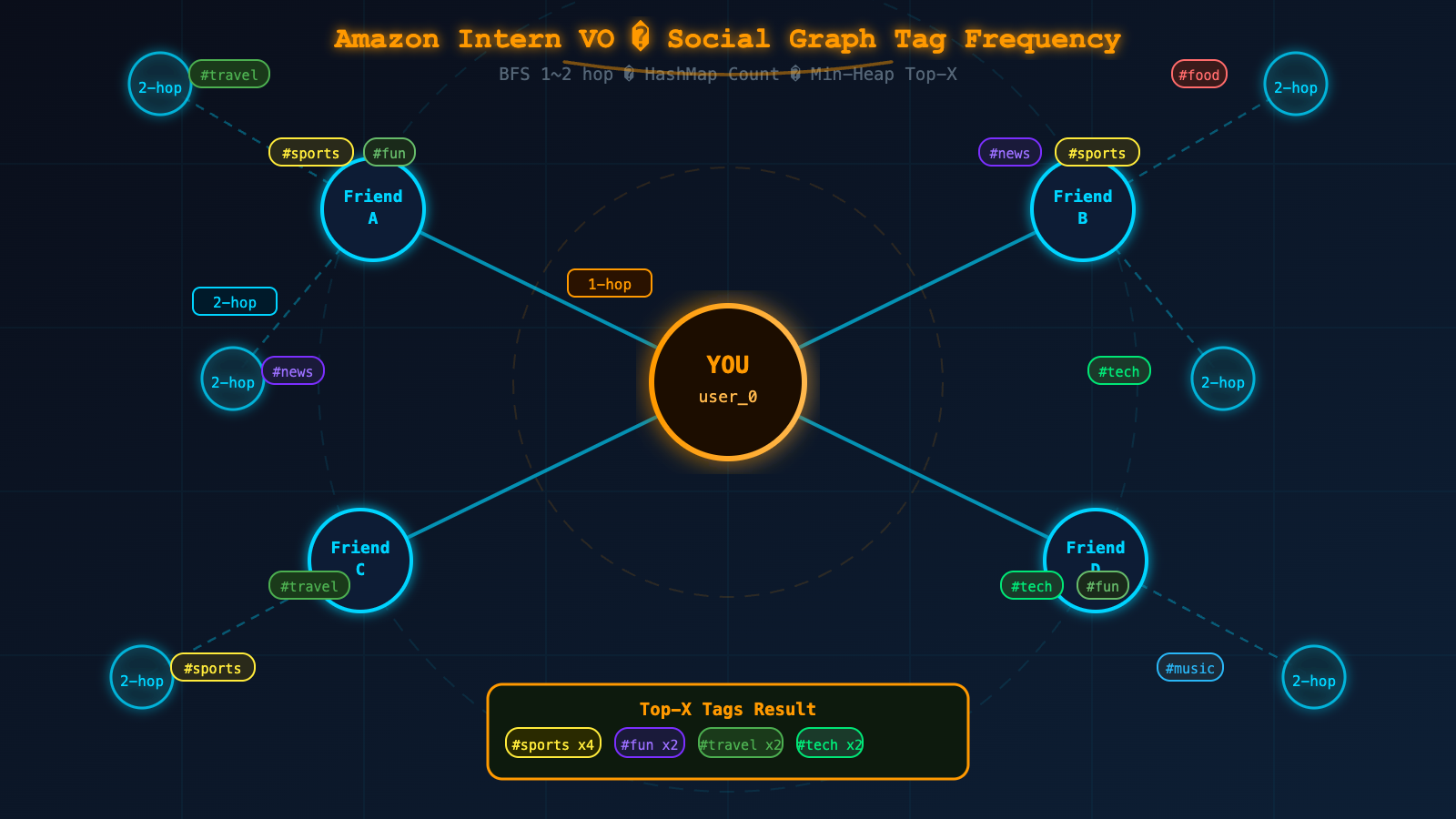
Given a user_id and an integer X, return the Top X most frequent tags used across all posts by:
- The user's direct friends (1-hop)
- The user's friends-of-friends (2-hop)
Note: Exclude the user themselves. If the same person is reachable via multiple paths, count their tags only once.
Example
user_0's friends: A, B
A's post tags: ["sports", "fun"]
B's post tags: ["news", "sports"]
A's friends: C
C's post tags: ["travel", "sports"]
X = 2
Aggregated tag frequencies:
sports : 3
fun : 1
news : 1
travel : 1
Top 2 output → ["sports", "fun"]
Approach
Three steps:
| Step | Action | Data Structure |
|---|---|---|
| 1 | BFS traverse 1~2-hop friends, collect all user IDs | deque + visited set |
| 2 | Iterate over those users' post tags, count frequencies | HashMap (Counter) |
| 3 | Retrieve Top X by frequency | Sort or min-heap |
Why BFS over DFS?
- BFS naturally expands layer by layer (hop by hop), making depth control straightforward — more intuitive code
- Only 2 layers needed here; BFS avoids recursion and stack overflow risk
- DFS is possible but requires extra depth tracking, which is error-prone
Why min-heap over full sort?
- Full sort: O(n log n), where n = number of distinct tags
- min-heap of size X: O(n log X)
- When X << n, heap is significantly better; mentioning this in an interview earns extra credit
Complete Python Solution
from collections import deque, Counter
import heapq
from typing import List, Dict
def top_tags_friends_and_fof(
user_id: str,
friends: Dict[str, List[str]], # user -> list of friend IDs
posts: Dict[str, List[List[str]]], # user -> list of posts, each post is a list of tags
X: int
) -> List[str]:
"""
Returns the Top X most frequent tags from posts of
user_id's 1-hop + 2-hop friends.
"""
# --- Step 1: BFS collect 1~2 hop friends ---
visited = {user_id} # exclude self
collected = set() # users whose tags we'll count
queue = deque()
# Add 1-hop friends
for friend in friends.get(user_id, []):
if friend not in visited:
visited.add(friend)
collected.add(friend)
queue.append(friend)
# Expand from 1-hop to 2-hop
while queue:
curr = queue.popleft()
for fof in friends.get(curr, []):
if fof not in visited:
visited.add(fof)
collected.add(fof)
# Do NOT enqueue further (stop at 2 hops)
# --- Step 2: Count tag frequencies ---
tag_count: Counter = Counter()
for uid in collected:
for post_tags in posts.get(uid, []):
tag_count.update(post_tags)
if not tag_count:
return []
# --- Step 3: Get Top X ---
# Method A: sort (concise)
top_x = [tag for tag, _ in tag_count.most_common(X)]
return top_x
def top_tags_heap(tag_count: Counter, X: int) -> List[str]:
"""
Method B: min-heap, O(n log X), better when X << n.
"""
heap = [] # (count, tag)
for tag, cnt in tag_count.items():
heapq.heappush(heap, (cnt, tag))
if len(heap) > X:
heapq.heappop(heap)
# Return remaining X items sorted by frequency descending
result = [tag for cnt, tag in sorted(heap, reverse=True)]
return result
Test Cases
if __name__ == "__main__":
friends_graph = {
"user_0": ["A", "B"],
"A": ["C", "D"],
"B": ["D"],
"C": [],
"D": [],
}
posts_data = {
"A": [["sports", "fun"]],
"B": [["news", "sports"]],
"C": [["travel", "sports"]],
"D": [["tech", "fun"]],
}
print(top_tags_friends_and_fof("user_0", friends_graph, posts_data, X=2))
# Expected: ['sports', 'fun'] (sports=3, fun=2)
print(top_tags_friends_and_fof("user_0", friends_graph, posts_data, X=3))
# Expected: ['sports', 'fun', 'news'] or similar (ties not guaranteed)
Complexity Analysis
| Phase | Time Complexity | Space Complexity |
|---|---|---|
| BFS collect friends | O(F + F²), F = 1-hop friend count | O(F²) |
| Count tag frequencies | O(T), T = total tag count across all posts | O(U) distinct tags |
| Top X (sort) | O(U log U) | O(U) |
| Top X (heap) | O(U log X) | O(X) |
| Overall | O(F² + T + U log X) | O(F² + U) |
Follow-up Questions
Q1: How to support 3-hop or K-hop?
Generalize BFS to K layers:
def bfs_k_hop(user_id, friends, K):
visited = {user_id}
collected = set()
queue = deque([(user_id, 0)])
while queue:
curr, depth = queue.popleft()
if depth >= K:
continue
for nb in friends.get(curr, []):
if nb not in visited:
visited.add(nb)
collected.add(nb)
queue.append((nb, depth + 1))
return collected
Q2: What if the graph is directed (Twitter follow relationship)?
Simply replace friends[curr] with following[curr] — traverse only in the follow direction. All other logic remains the same.
Q3: How to scale to hundreds of millions of users?
- Graph storage: Distributed graph DB (e.g. Amazon Neptune / DynamoDB)
- Parallel BFS: Fetch friend lists concurrently per layer, coordinate via message queue
- Frequency counting: MapReduce or Spark, count per partition then merge
- Top-X: Local Top-X per node, then global merge
Q4: What if each user's tags should be deduplicated (each tag counts at most once per user)?
for uid in collected:
user_tags = set()
for post_tags in posts.get(uid, []):
user_tags.update(post_tags)
tag_count.update(user_tags) # each tag contributes at most 1 per user
Common Mistakes
| Mistake | Consequence | Fix |
|---|---|---|
No visited deduplication |
Same user's tags counted multiple times | Maintain visited set during BFS |
Including user_id themselves |
Own tags pollute the result | Initialize visited = {user_id} |
| Enqueuing 2-hop nodes for further expansion | Becomes 3-hop or infinite traversal | Stop at 2 hops: collect but don't enqueue |
| Only using sort, never mentioning heap | Miss O(n log X) optimization opportunity | Proactively propose heap solution with complexity comparison |
Interview Strategy
Clarify Upfront (2 minutes)
- Is the friendship graph directed or undirected?
- If the same user is reachable via multiple paths, count tags once or multiple times?
- How to handle ties in Top X (usually not required to be stable)?
- Are there cycles? (Undirected graphs always have them —
visitedis essential)
How to Structure Your Explanation
- State the big picture first: BFS → HashMap → Heap
- Walk through an example before writing code
- After the basic version, proactively optimize: discuss heap vs full sort
- At the end, state complexity and bring up follow-ups
Bonus Points
- Explain why
visiteddeduplication is necessary, and whyuser_idmust be in the initialvisitedset - Write both
most_common(X)and min-heap variants, then compare them - Voluntarily discuss distributed scaling for billions of users (shows system design awareness)
Related LeetCode Problems
| # | Problem | Connection |
|---|---|---|
| 347 | Top K Frequent Elements | Frequency count + heap |
| 994 | Rotting Oranges | BFS layer traversal |
| 133 | Clone Graph | Graph BFS/DFS + visited |
| 1091 | Shortest Path in Binary Matrix | BFS shortest path |
| 692 | Top K Frequent Words | Top-K strings |
Why Does Amazon Love Social Graph Problems?
Amazon's business is deeply graph-structured: recommendation systems ("customers who bought A also bought B"), seller networks, logistics nodes, and more. The social graph Top-K tags problem is essentially a simplified recommendation engine — surfacing the most popular topic tags based on a user's social circle, which is conceptually identical to the underlying logic of Amazon Personalize.
Understanding this problem goes beyond interview prep — it gives you genuine intuition for cold-start problems and collaborative filtering in real recommendation systems.
🚀 Need Amazon Intern VO Assistance?
oavoservice specializes in full-service OA/VO support for North American big tech companies. Amazon Intern/NG is one of our most common service scenarios.
Add WeChat now: Coding0201
What you get:
- ✅ Amazon VO real-time assistance (screen share + live typing prompts)
- ✅ Verified question bank (including 2026 latest Intern VO problems)
- ✅ 1-on-1 mock interviews + detailed feedback
- ✅ Leadership Principles behavioral question coaching
📱 WeChat: Coding0201 | 💬 Telegram: @OAVOProxy | 📧 [email protected]
联系方式
Email: [email protected] Telegram: @OAVOProxy