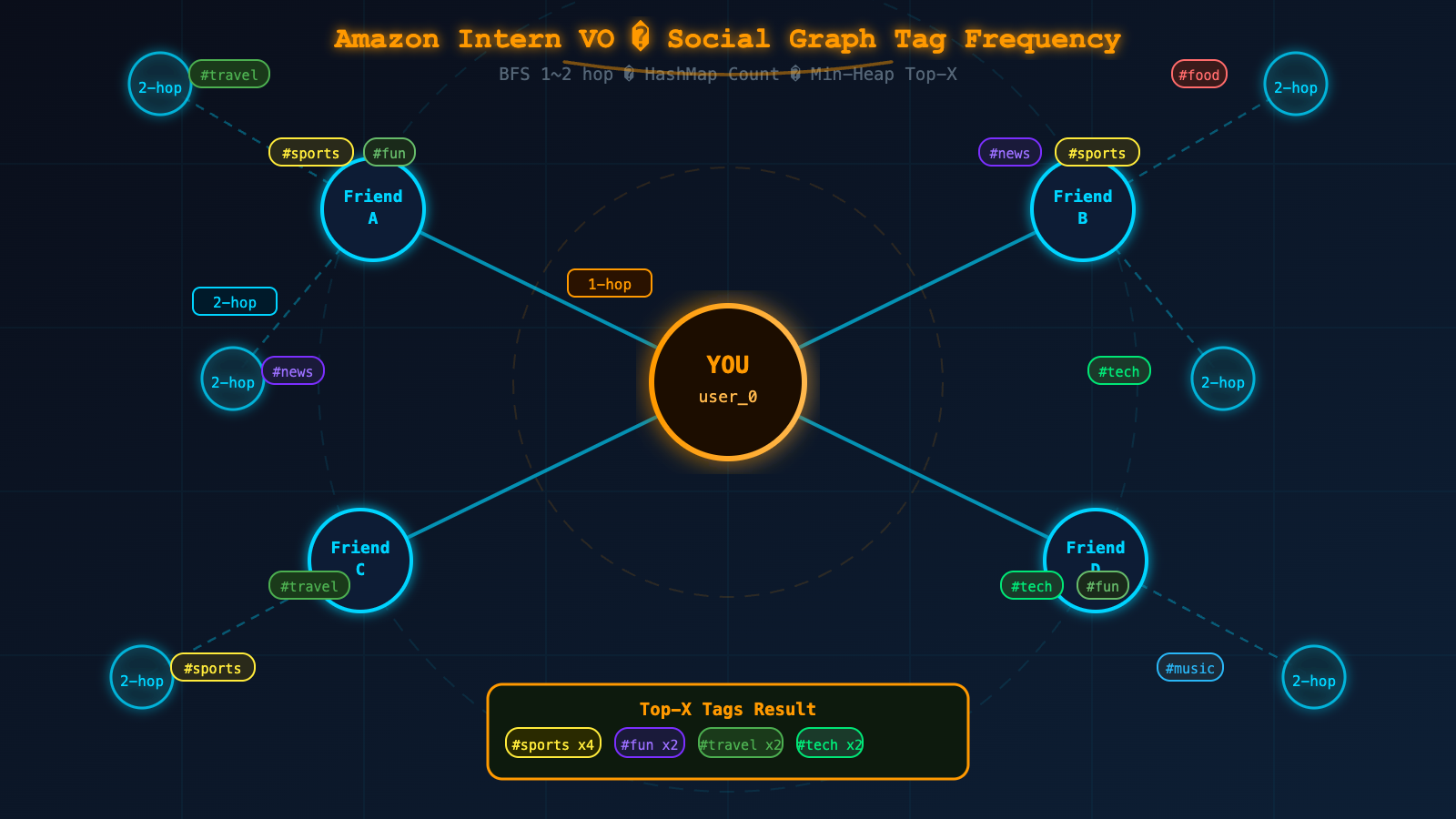
Amazon Intern VO Round 1 真题:统计好友及二度好友最常用标签 Top X
本题来自 Amazon 2026 Intern Virtual Onsite Round 1,考察图遍历(BFS)、哈希表频次统计与堆(Heap)的综合运用,是社交网络场景下的经典 Top-K 问题。
题目描述
Imagine you have a Twitter-style social network. Each user has a list of friends, and each user has posted some posts. Each post can carry multiple tags.
Your task:
Given a user_id and an integer X, return the Top X most frequent tags used across all posts by:
- The user's direct friends (1-hop)
- The user's friends-of-friends (2-hop)
注意:不统计用户本人的标签。如果同一个人通过多条路径可达,其标签只计一次。
示例
用户 user_0 的朋友:A, B
A 的帖子标签:["sports", "fun"]
B 的帖子标签:["news", "sports"]
A 的朋友:C
C 的帖子标签:["travel", "sports"]
X = 2
聚合后标签频次:
sports : 3
fun : 1
news : 1
travel : 1
Top 2 输出 → ["sports", "fun"] (fun/news/travel 频次相同时按字典序或题意处理)
解题思路
整体三步走:
| 步骤 | 操作 | 数据结构 |
|---|---|---|
| 1 | BFS 遍历 1~2 跳好友,收集所有用户 ID | deque + visited set |
| 2 | 遍历这些用户的所有帖子标签,统计频次 | HashMap (Counter) |
| 3 | 取频次最高的 Top X 个标签 | 排序 或 min-heap |
为什么用 BFS 而非 DFS?
- BFS 天然按层(hop)扩展,控制层数只需控制队列深度,代码更直观
- 本题只需 2 层,BFS 无需递归,栈溢出风险低
- DFS 也可行,但需要额外维护当前深度,易出 bug
为什么用 min-heap 而非全排序?
- 全排序:O(n log n),n 为不同标签数
- min-heap 维护大小为 X 的堆:O(n log X)
- 当 X << n 时,heap 明显更优;面试中提出这一点会加分
完整 Python 代码
from collections import deque, Counter
import heapq
from typing import List, Dict
def top_tags_friends_and_fof(
user_id: str,
friends: Dict[str, List[str]], # user -> list of friend IDs
posts: Dict[str, List[List[str]]],# user -> list of posts, each post is list of tags
X: int
) -> List[str]:
"""
返回 user_id 的 1-hop + 2-hop 好友帖子中频次最高的 Top X 标签。
"""
# --- Step 1: BFS 收集 1~2 hop 好友 ---
visited = {user_id} # 排除自身
collected = set() # 需要统计标签的用户集合
queue = deque()
# 加入 1-hop 好友
for friend in friends.get(user_id, []):
if friend not in visited:
visited.add(friend)
collected.add(friend)
queue.append(friend)
# 从 1-hop 扩展到 2-hop
while queue:
curr = queue.popleft()
for fof in friends.get(curr, []):
if fof not in visited:
visited.add(fof)
collected.add(fof)
# 不再继续扩展(只到 2 hop)
# --- Step 2: 统计标签频次 ---
tag_count: Counter = Counter()
for uid in collected:
for post_tags in posts.get(uid, []):
tag_count.update(post_tags)
if not tag_count:
return []
# --- Step 3: 取 Top X ---
# 方法 A:直接排序(简洁)
top_x = [tag for tag, _ in tag_count.most_common(X)]
return top_x
def top_tags_heap(tag_count: Counter, X: int) -> List[str]:
"""
方法 B:min-heap,O(n log X),X << n 时更优。
"""
heap = [] # (count, tag)
for tag, cnt in tag_count.items():
heapq.heappush(heap, (cnt, tag))
if len(heap) > X:
heapq.heappop(heap)
# heap 中剩余 X 个,按频次降序输出
result = [tag for cnt, tag in sorted(heap, reverse=True)]
return result
测试用例
if __name__ == "__main__":
friends_graph = {
"user_0": ["A", "B"],
"A": ["C", "D"],
"B": ["D"],
"C": [],
"D": [],
}
posts_data = {
"A": [["sports", "fun"]],
"B": [["news", "sports"]],
"C": [["travel", "sports"]],
"D": [["tech", "fun"]],
}
print(top_tags_friends_and_fof("user_0", friends_graph, posts_data, X=2))
# 预期: ['sports', 'fun'] (sports=3, fun=2)
print(top_tags_friends_and_fof("user_0", friends_graph, posts_data, X=3))
# 预期: ['sports', 'fun', 'news'] 或 ['sports', 'fun', 'travel'] 等(频次相同时不保证顺序)
复杂度分析
| 阶段 | 时间复杂度 | 空间复杂度 |
|---|---|---|
| BFS 收集好友 | O(F + F²),F = 1-hop 好友数 | O(F²) |
| 统计标签频次 | O(T),T = 所有帖子标签总数 | O(U) 不同标签数 |
| 取 Top X(排序) | O(U log U) | O(U) |
| 取 Top X(heap) | O(U log X) | O(X) |
| 整体 | O(F² + T + U log X) | O(F² + U) |
Follow-up 问题与回答
Q1:如果要支持 3-hop 甚至 K-hop 怎么办?
将 BFS 改为通用 K 层扩展:
def bfs_k_hop(user_id, friends, K):
visited = {user_id}
collected = set()
queue = deque([(user_id, 0)])
while queue:
curr, depth = queue.popleft()
if depth >= K:
continue
for nb in friends.get(curr, []):
if nb not in visited:
visited.add(nb)
collected.add(nb)
queue.append((nb, depth + 1))
return collected
Q2:如果图是有向图(Twitter follow 关系),该怎么处理?
只需将 friends[curr] 替换为 following[curr](只沿 follow 方向扩展),其余逻辑不变。
Q3:如果用户量达到亿级,如何扩展?
- 图存储:分布式图数据库(如 Amazon Neptune / DynamoDB)
- BFS 并行化:按层并发拉取好友列表,用消息队列协调
- 频次统计:MapReduce 或 Spark,各 partition 分别统计后 merge
- Top-X:各节点局部 Top-X,最终 merge 取全局 Top-X
Q4:如果同一用户的标签需要去重(每个标签每人只算一次)?
在统计时改为 set 去重:
for uid in collected:
user_tags = set()
for post_tags in posts.get(uid, []):
user_tags.update(post_tags)
tag_count.update(user_tags) # 每人每个标签最多贡献 1
常见错误
| 错误 | 后果 | 正确做法 |
|---|---|---|
未用 visited 去重 |
同一用户标签重复计算,答案错误 | BFS 时维护 visited set |
将 user_id 本人加入统计 |
多统计了自己的标签 | 初始化 visited = {user_id} |
| 2-hop 节点继续入队扩展 | 变成 3-hop 甚至无限 | BFS 控制层数,2-hop 只收集不再入队 |
| 只用排序不提 heap | 错过 O(n log X) 优化机会 | 主动提出 heap 方案并分析复杂度 |
面试策略
开场澄清(2 分钟)
拿到题目先确认:
- 好友关系是有向还是无向?
- 同一用户多次可达时,标签算一次还是多次?
- Top X 有并列时如何处理(题目不要求稳定排序时不必纠结)?
- 图中是否有环(无向图必有,需要 visited 去重)?
思路表达顺序
- 先说大框架:BFS → HashMap → Heap
- 写代码前举例走一遍(白板或口述)
- 写完基本版本后主动优化:提出 heap vs 全排序
- 收尾时主动讲复杂度,再提 Follow-up
加分点
- 提出
visited去重的必要性,并解释为什么初始化时要把user_id本身放进去 - 将
most_common(X)和 min-heap 两种方案都写出来,并对比 - 主动提出亿级用户的分布式扩展思路(体现系统设计意识)
相关 LeetCode 题目
| 题号 | 题目 | 关联点 |
|---|---|---|
| 347 | Top K Frequent Elements | 频次统计 + heap |
| 994 | Rotting Oranges | BFS 层级遍历 |
| 133 | Clone Graph | 图 BFS/DFS + visited |
| 1091 | Shortest Path in Binary Matrix | BFS 最短路 |
| 692 | Top K Frequent Words | Top-K 字符串 |
延伸思考:为什么 Amazon 爱出社交图题?
Amazon 的业务场景中大量涉及图结构:推荐系统(买了 A 的人还买了 B)、商家网络、物流节点等。社交图 Top-K 标签这道题,实质上是推荐系统的简化版——根据用户的社交圈兴趣,推荐最热门的话题标签,与 Amazon Personalize 的底层逻辑一脉相承。
理解这道题,不只是为了应付面试——它能帮你真正理解推荐系统的冷启动问题和协同过滤的直觉基础。
🚀 需要 Amazon Intern VO 辅助?
oavoservice 专注北美大厂 OA/VO 全程辅助,Amazon Intern/NG 是我们的高频服务场景。
立即添加微信:Coding0201
获取:
- ✅ Amazon VO 实时辅助(屏幕共享 + 实时打字提示)
- ✅ 真实题库(含 2026 最新 Intern VO 题目)
- ✅ 一对一模拟面试 + 详细反馈
- ✅ Leadership Principles 行为题专项训练
📱 微信:Coding0201 | 💬 Telegram:@OAVOProxy | 📧 [email protected]
联系方式
Email: [email protected] Telegram: @OAVOProxy