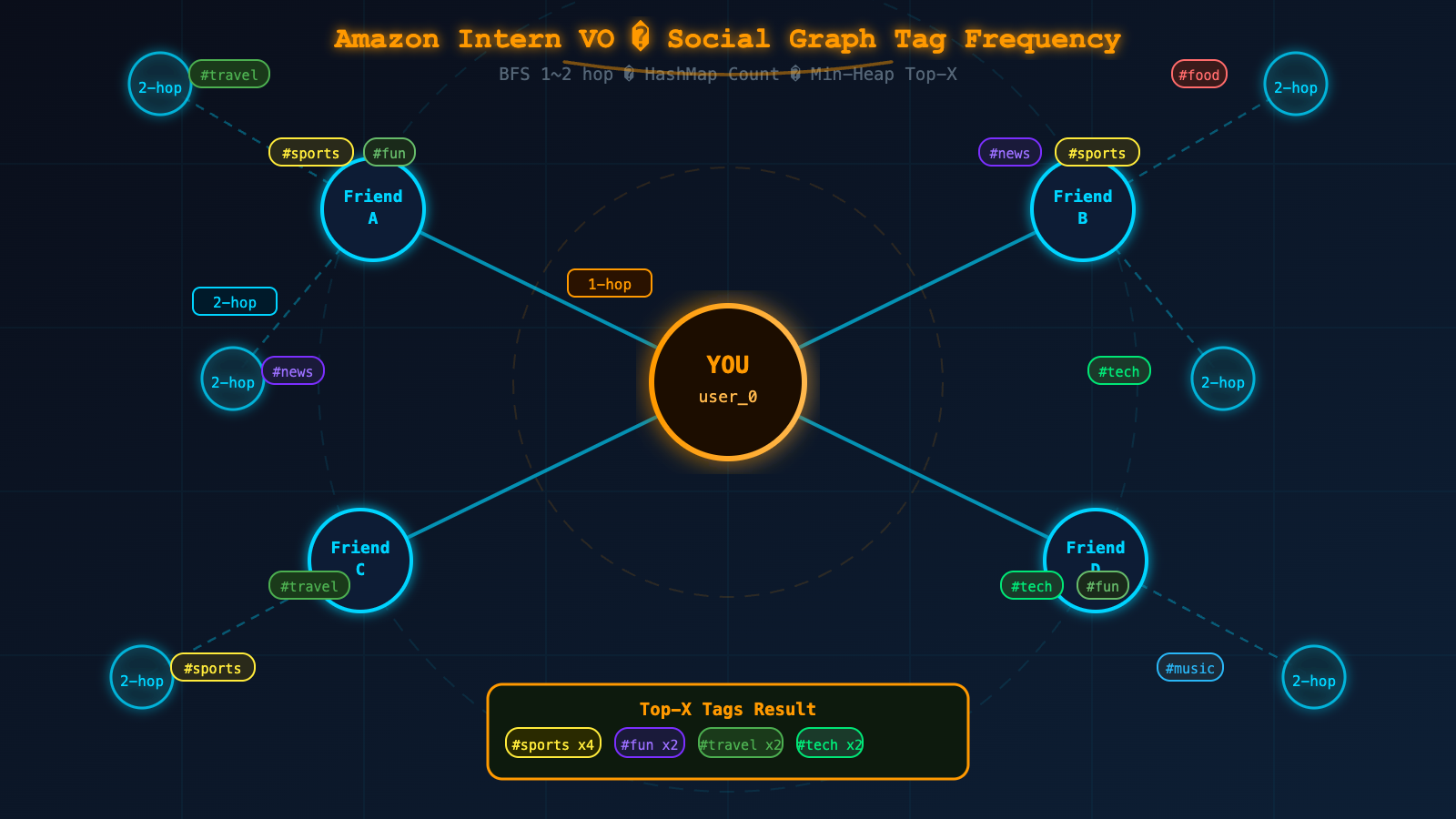
Amazon Intern VO Round 1 真題:統計好友及二度好友最常用標籤 Top X
本題來自 Amazon 2026 Intern Virtual Onsite Round 1,考察圖遍歷(BFS)、雜湊表頻次統計與堆(Heap)的綜合運用,是社交網路場景下的經典 Top-K 問題。
題目描述
Imagine you have a Twitter-style social network. Each user has a list of friends, and each user has posted some posts. Each post can carry multiple tags.
Your task:
Given a user_id and an integer X, return the Top X most frequent tags used across all posts by:
- The user's direct friends (1-hop)
- The user's friends-of-friends (2-hop)
注意:不統計使用者本人的標籤。如果同一個人透過多條路徑可達,其標籤只計一次。
範例
使用者 user_0 的朋友:A, B
A 的貼文標籤:["sports", "fun"]
B 的貼文標籤:["news", "sports"]
A 的朋友:C
C 的貼文標籤:["travel", "sports"]
X = 2
聚合後標籤頻次:
sports : 3
fun : 1
news : 1
travel : 1
Top 2 輸出 → ["sports", "fun"]
解題思路
整體三步走:
| 步驟 | 操作 | 資料結構 |
|---|---|---|
| 1 | BFS 遍歷 1~2 跳好友,收集所有使用者 ID | deque + visited set |
| 2 | 遍歷這些使用者的所有貼文標籤,統計頻次 | HashMap (Counter) |
| 3 | 取頻次最高的 Top X 個標籤 | 排序 或 min-heap |
為什麼用 BFS 而非 DFS?
- BFS 天然按層(hop)擴展,控制層數只需控制佇列深度,程式碼更直觀
- 本題只需 2 層,BFS 無需遞迴,堆疊溢位風險低
- DFS 也可行,但需要額外維護當前深度,容易出 bug
為什麼用 min-heap 而非全排序?
- 全排序:O(n log n),n 為不同標籤數
- min-heap 維護大小為 X 的堆:O(n log X)
- 當 X << n 時,heap 明顯更優;面試中提出這一點會加分
完整 Python 程式碼
from collections import deque, Counter
import heapq
from typing import List, Dict
def top_tags_friends_and_fof(
user_id: str,
friends: Dict[str, List[str]],
posts: Dict[str, List[List[str]]],
X: int
) -> List[str]:
visited = {user_id}
collected = set()
queue = deque()
for friend in friends.get(user_id, []):
if friend not in visited:
visited.add(friend)
collected.add(friend)
queue.append(friend)
while queue:
curr = queue.popleft()
for fof in friends.get(curr, []):
if fof not in visited:
visited.add(fof)
collected.add(fof)
tag_count: Counter = Counter()
for uid in collected:
for post_tags in posts.get(uid, []):
tag_count.update(post_tags)
if not tag_count:
return []
return [tag for tag, _ in tag_count.most_common(X)]
def top_tags_heap(tag_count: Counter, X: int) -> List[str]:
heap = []
for tag, cnt in tag_count.items():
heapq.heappush(heap, (cnt, tag))
if len(heap) > X:
heapq.heappop(heap)
return [tag for cnt, tag in sorted(heap, reverse=True)]
測試案例
if __name__ == "__main__":
friends_graph = {
"user_0": ["A", "B"],
"A": ["C", "D"],
"B": ["D"],
"C": [],
"D": [],
}
posts_data = {
"A": [["sports", "fun"]],
"B": [["news", "sports"]],
"C": [["travel", "sports"]],
"D": [["tech", "fun"]],
}
print(top_tags_friends_and_fof("user_0", friends_graph, posts_data, X=2))
# 預期: ['sports', 'fun']
複雜度分析
| 階段 | 時間複雜度 | 空間複雜度 |
|---|---|---|
| BFS 收集好友 | O(F + F²) | O(F²) |
| 統計標籤頻次 | O(T) | O(U) |
| 取 Top X(排序) | O(U log U) | O(U) |
| 取 Top X(heap) | O(U log X) | O(X) |
| 整體 | O(F² + T + U log X) | O(F² + U) |
Follow-up 問題與回答
Q1:如果要支援 K-hop 怎麼辦?
def bfs_k_hop(user_id, friends, K):
visited = {user_id}
collected = set()
queue = deque([(user_id, 0)])
while queue:
curr, depth = queue.popleft()
if depth >= K:
continue
for nb in friends.get(curr, []):
if nb not in visited:
visited.add(nb)
collected.add(nb)
queue.append((nb, depth + 1))
return collected
Q2:有向圖(Twitter follow)怎麼處理?
將 friends[curr] 替換為 following[curr] 即可,其餘邏輯不變。
Q3:億級使用者如何擴展?
- 圖儲存:Amazon Neptune / DynamoDB
- BFS 並行化:按層並發 + 訊息佇列
- 頻次統計:MapReduce / Spark partition 後 merge
- Top-X:局部 Top-X 後全域 merge
Q4:每位使用者的標籤需要去重?
for uid in collected:
user_tags = set()
for post_tags in posts.get(uid, []):
user_tags.update(post_tags)
tag_count.update(user_tags)
常見錯誤
| 錯誤 | 後果 | 正確做法 |
|---|---|---|
未用 visited 去重 |
標籤重複計算 | BFS 維護 visited set |
| 將本人加入統計 | 多統計自己的標籤 | 初始化 visited = {user_id} |
| 2-hop 繼續入佇列 | 變成無限擴展 | 2-hop 只收集不入佇列 |
| 只用排序不提 heap | 錯過最佳化機會 | 主動提出 heap 並分析複雜度 |
面試策略
開場澄清(2 分鐘)
- 好友關係是有向還是無向?
- 同一使用者多次可達時,標籤算幾次?
- Top X 並列時如何處理?
- 圖中是否有環?
思路表達順序
- 說大框架:BFS → HashMap → Heap
- 舉例走一遍再寫程式碼
- 主動提出 heap 最佳化
- 收尾講複雜度 + Follow-up
加分點
- 解釋
visited必要性及初始化原因 - 同時展示
most_common與 min-heap 兩種方案並比較 - 主動提出億級分散式擴展思路
相關 LeetCode 題目
| 題號 | 題目 | 關聯點 |
|---|---|---|
| 347 | Top K Frequent Elements | 頻次統計 + heap |
| 994 | Rotting Oranges | BFS 層級遍歷 |
| 133 | Clone Graph | 圖 BFS/DFS + visited |
| 1091 | Shortest Path in Binary Matrix | BFS 最短路 |
| 692 | Top K Frequent Words | Top-K 字串 |
延伸思考:為什麼 Amazon 愛出社交圖題?
Amazon 的業務場景中大量涉及圖結構:推薦系統(買了 A 的人還買了 B)、商家網路、物流節點等。社交圖 Top-K 標籤這道題,實質上是推薦系統的簡化版——根據使用者的社交圈興趣,推薦最熱門的話題標籤,與 Amazon Personalize 的底層邏輯一脈相承。
理解這道題,不只是為了應付面試——它能幫你真正理解推薦系統的冷啟動問題和協同過濾的直覺基礎。
🚀 需要 Amazon Intern VO 輔助?
oavoservice 專注北美大廠 OA/VO 全程輔助,Amazon Intern/NG 是我們的高頻服務場景。
立即加 WeChat:Coding0201
獲取:
- ✅ Amazon VO 即時輔助(螢幕共享 + 即時打字提示)
- ✅ 真實題庫(含 2026 最新 Intern VO 題目)
- ✅ 一對一模擬面試 + 詳細回饋
- ✅ Leadership Principles 行為題專項訓練
📱 WeChat:Coding0201 | 💬 Telegram:@OAVOProxy | 📧 [email protected]
联系方式
Email: [email protected] Telegram: @OAVOProxy