
题目概述
这是Meta的经典OA题目,考察对文件系统设计和数据结构的理解。整个题目分为4个难度等级,从基础的文件操作逐步升级到复杂的用户容量管理和文件压缩。
时间分配建议:
- Level 1:15-20分钟
- Level 2:20-25分钟
- Level 3:25-30分钟
- Level 4:15-20分钟
Level 1:基础文件操作
题目要求
实现一个内存云存储系统,支持三个基础操作:
add_file(self, name: str, size: int) -> bool- 添加新文件到存储系统
- 返回
True如果添加成功,False如果文件已存在
copy_file(self, name_from: str, name_to: str) -> bool- 复制文件从
name_from到name_to - 如果源文件不存在或目标文件已存在,返回
False - 返回
True如果复制成功
- 复制文件从
get_file_size(self, name: str) -> int | None- 返回文件大小,如果文件不存在返回
None
- 返回文件大小,如果文件不存在返回
解题思路
这是最基础的题目,直接使用**哈希表(字典)**存储文件即可。
class CloudStorage:
def __init__(self):
self.files = {} # {filename: size}
def add_file(self, name: str, size: int) -> bool:
if name in self.files:
return False
self.files[name] = size
return True
def copy_file(self, name_from: str, name_to: str) -> bool:
# 源文件不存在
if name_from not in self.files:
return False
# 目标文件已存在
if name_to in self.files:
return False
# 复制文件
self.files[name_to] = self.files[name_from]
return True
def get_file_size(self, name: str) -> int | None:
return self.files.get(name)
时间复杂度分析
| 操作 | 时间复杂度 | 空间复杂度 |
|---|---|---|
add_file |
O(1) | O(1) |
copy_file |
O(1) | O(1) |
get_file_size |
O(1) | - |
常见陷阱
❌ 忘记检查源文件是否存在
❌ 忘记检查目标文件是否已存在
✅ 使用字典的 get() 方法处理不存在的键
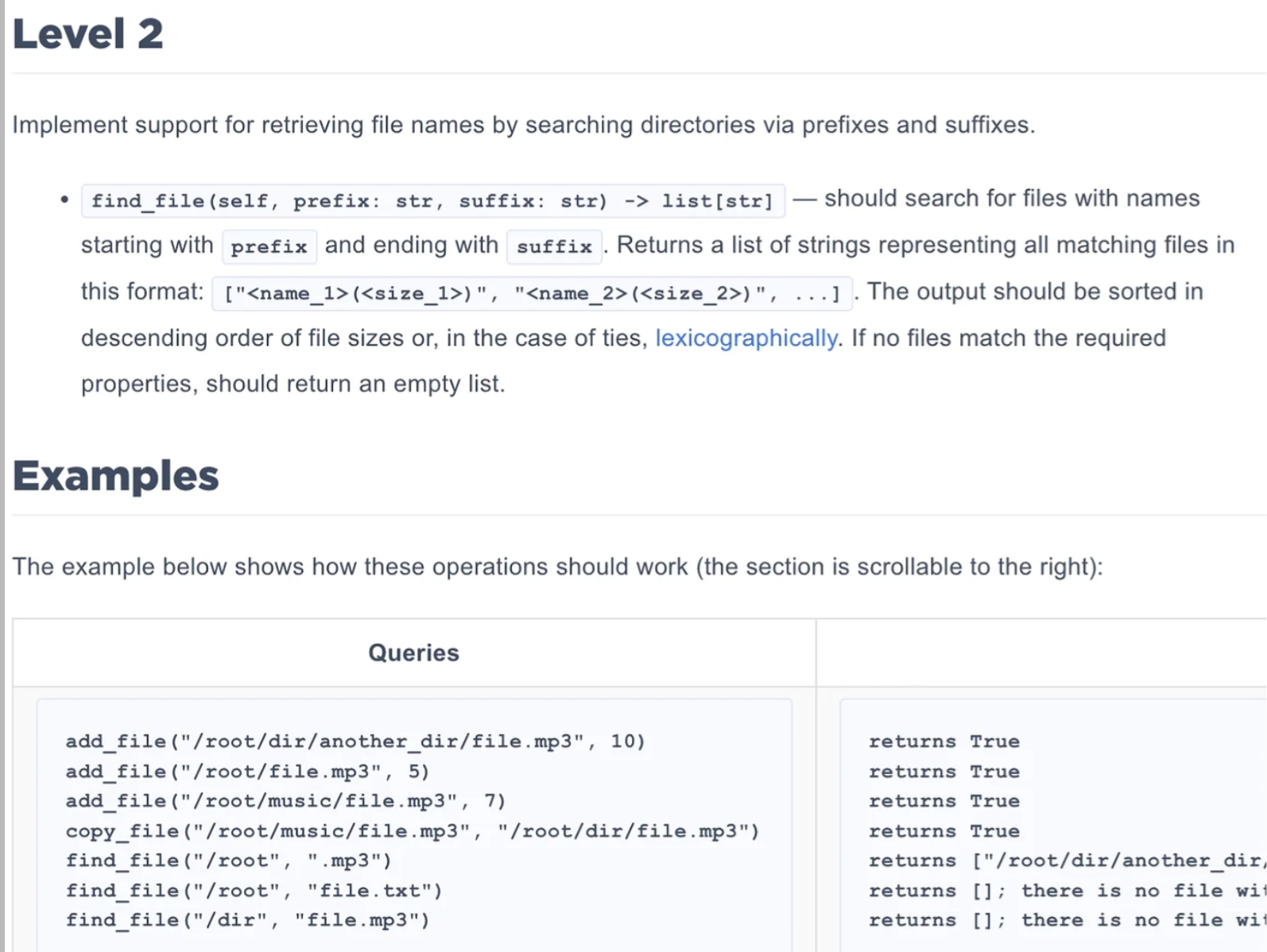
Level 2:前缀后缀搜索

题目要求
在Level 1的基础上,添加文件搜索功能:
find_file(self, prefix: str, suffix: str) -> list[str]
- 搜索所有以
prefix开头且以suffix结尾的文件 - 返回格式:
["<name_1>(<size_1>)", "<name_2>(<size_2>)", ...] - 按文件大小降序排列,相同大小按字典序排列
- 如果没有匹配的文件,返回空列表
解题思路
关键是高效的字符串匹配和正确的排序。
def find_file(self, prefix: str, suffix: str) -> list[str]:
result = []
# 遍历所有文件,找出匹配的
for name, size in self.files.items():
if name.startswith(prefix) and name.endswith(suffix):
result.append((name, size))
# 按大小降序,相同大小按名字字典序排列
result.sort(key=lambda x: (-x[1], x[0]))
# 格式化输出
return [f"{name}({size})" for name, size in result]
优化方案
对于大规模文件系统,可以使用Trie树或后缀树优化搜索,但在OA考试中通常不需要。
# 简单优化:预先过滤
def find_file(self, prefix: str, suffix: str) -> list[str]:
result = [
(name, size)
for name, size in self.files.items()
if name.startswith(prefix) and name.endswith(suffix)
]
result.sort(key=lambda x: (-x[1], x[0]))
return [f"{name}({size})" for name, size in result]
时间复杂度分析
| 操作 | 时间复杂度 | 说明 |
|---|---|---|
| 搜索 | O(n·m) | n=文件数,m=平均名字长度 |
| 排序 | O(k·log k) | k=匹配的文件数 |
| 总体 | O(n·m + k·log k) | - |
常见陷阱
❌ 排序顺序错误(应该是大小降序,名字升序)
❌ 忘记格式化输出字符串
❌ 使用 in 检查子串(应该用 startswith/endswith)
✅ 使用 sort(key=lambda x: (-x[1], x[0])) 实现双重排序
Level 3:用户容量管理

题目要求
支持多用户和容量限制:
add_user(self, user_id: str, capacity: int) -> bool- 添加新用户,分配存储容量
- 用户已存在返回
False
add_file_by(self, user_id: str, name: str, size: int) -> int | None- 用户添加文件,返回剩余容量
- 如果超过容量限制,返回
None - 注意:Level 1的
add_file操作由user_id="admin"执行,容量无限
update_capacity(self, user_id: str, capacity: int) -> int | None- 更新用户容量
- 如果新容量不足以容纳现有文件,删除最大的文件(字典序作为tiebreaker)
- 返回删除的文件数,用户不存在返回
None
解题思路
需要维护用户-文件映射和容量追踪。
class CloudStorage:
def __init__(self):
self.files = {} # {filename: size}
self.users = {} # {user_id: capacity}
self.user_files = {} # {user_id: {filename: size}}
def add_user(self, user_id: str, capacity: int) -> bool:
if user_id in self.users:
return False
self.users[user_id] = capacity
self.user_files[user_id] = {}
return True
def add_file_by(self, user_id: str, name: str, size: int) -> int | None:
if user_id not in self.users:
return None
# 计算用户已使用的容量
used = sum(self.user_files[user_id].values())
remaining = self.users[user_id] - used
# 容量不足
if size > remaining:
return None
# 添加文件
self.user_files[user_id][name] = size
self.files[name] = size
return remaining - size
def update_capacity(self, user_id: str, capacity: int) -> int | None:
if user_id not in self.users:
return None
self.users[user_id] = capacity
# 计算需要删除的文件
used = sum(self.user_files[user_id].values())
if used <= capacity:
return 0
# 按大小降序,名字升序排列
files_list = sorted(
self.user_files[user_id].items(),
key=lambda x: (-x[1], x[0])
)
removed_count = 0
for name, size in files_list:
if used <= capacity:
break
# 删除文件
del self.user_files[user_id][name]
del self.files[name]
used -= size
removed_count += 1
return removed_count
关键点
- 容量计算:
remaining = capacity - sum(user_files) - 删除策略:删除最大的文件,相同大小按字典序
- 文件所有权:复制文件时保留原所有者
时间复杂度分析
| 操作 | 时间复杂度 |
|---|---|
add_user |
O(1) |
add_file_by |
O(1) |
update_capacity |
O(k·log k) |
Level 4:文件压缩与解压
题目要求
添加文件压缩功能:
compress_file(self, name: str) -> bool- 压缩文件,大小变为原来的一半(向下取整)
- 文件不存在返回
False
decompress_file(self, name: str) -> bool- 解压文件,恢复原始大小
- 文件不存在或未压缩返回
False
解题思路
需要追踪文件的压缩状态和原始大小。
class CloudStorage:
def __init__(self):
self.files = {} # {filename: size}
self.original_size = {} # {filename: original_size}
self.is_compressed = {} # {filename: bool}
self.users = {}
self.user_files = {}
def add_file(self, name: str, size: int) -> bool:
if name in self.files:
return False
self.files[name] = size
self.original_size[name] = size
self.is_compressed[name] = False
return True
def compress_file(self, name: str) -> bool:
if name not in self.files:
return False
if self.is_compressed[name]:
return False
# 压缩文件
self.files[name] = self.files[name] // 2
self.is_compressed[name] = True
return True
def decompress_file(self, name: str) -> bool:
if name not in self.files:
return False
if not self.is_compressed[name]:
return False
# 解压文件
self.files[name] = self.original_size[name]
self.is_compressed[name] = False
return True
容量管理中的压缩
在 add_file_by 中需要考虑压缩状态:
def add_file_by(self, user_id: str, name: str, size: int) -> int | None:
if user_id not in self.users:
return None
# 计算实际使用的容量(考虑压缩)
used = sum(
self.files[fname] for fname in self.user_files[user_id]
)
remaining = self.users[user_id] - used
if size > remaining:
return None
self.user_files[user_id][name] = size
self.files[name] = size
self.original_size[name] = size
self.is_compressed[name] = False
return remaining - size
完整代码实现
class CloudStorage:
def __init__(self):
self.files = {}
self.original_size = {}
self.is_compressed = {}
self.users = {}
self.user_files = {}
# Level 1
def add_file(self, name: str, size: int) -> bool:
if name in self.files:
return False
self.files[name] = size
self.original_size[name] = size
self.is_compressed[name] = False
return True
def copy_file(self, name_from: str, name_to: str) -> bool:
if name_from not in self.files or name_to in self.files:
return False
self.files[name_to] = self.files[name_from]
self.original_size[name_to] = self.original_size[name_from]
self.is_compressed[name_to] = self.is_compressed[name_from]
return True
def get_file_size(self, name: str) -> int | None:
return self.files.get(name)
# Level 2
def find_file(self, prefix: str, suffix: str) -> list[str]:
result = [
(name, self.files[name])
for name in self.files
if name.startswith(prefix) and name.endswith(suffix)
]
result.sort(key=lambda x: (-x[1], x[0]))
return [f"{name}({size})" for name, size in result]
# Level 3
def add_user(self, user_id: str, capacity: int) -> bool:
if user_id in self.users:
return False
self.users[user_id] = capacity
self.user_files[user_id] = {}
return True
def add_file_by(self, user_id: str, name: str, size: int) -> int | None:
if user_id not in self.users:
return None
used = sum(self.files[f] for f in self.user_files[user_id])
remaining = self.users[user_id] - used
if size > remaining:
return None
self.user_files[user_id][name] = size
self.files[name] = size
self.original_size[name] = size
self.is_compressed[name] = False
return remaining - size
def update_capacity(self, user_id: str, capacity: int) -> int | None:
if user_id not in self.users:
return None
self.users[user_id] = capacity
used = sum(self.files[f] for f in self.user_files[user_id])
if used <= capacity:
return 0
files_list = sorted(
self.user_files[user_id].items(),
key=lambda x: (-self.files[x[0]], x[0])
)
removed = 0
for name, _ in files_list:
if used <= capacity:
break
used -= self.files[name]
del self.user_files[user_id][name]
del self.files[name]
removed += 1
return removed
# Level 4
def compress_file(self, name: str) -> bool:
if name not in self.files or self.is_compressed[name]:
return False
self.files[name] //= 2
self.is_compressed[name] = True
return True
def decompress_file(self, name: str) -> bool:
if name not in self.files or not self.is_compressed[name]:
return False
self.files[name] = self.original_size[name]
self.is_compressed[name] = False
return True
临场应对策略
时间管理
| 阶段 | 时间 | 任务 |
|---|---|---|
| 0-5分钟 | 5分 | 理解题意,明确需求 |
| 5-25分钟 | 20分 | 完成Level 1-2 |
| 25-55分钟 | 30分 | 完成Level 3 |
| 55-85分钟 | 30分 | 完成Level 4 + 测试 |
| 85-90分钟 | 5分 | 检查代码,提交 |
常见错误
❌ 容量计算错误:忘记考虑压缩状态
❌ 排序顺序混乱:大小降序 + 名字升序
❌ 文件所有权混淆:复制文件时保留原所有者
❌ 边界条件遗漏:用户不存在、文件不存在等
✅ 最佳实践:
- 先完成基础功能,再逐步添加复杂逻辑
- 每完成一个Level就测试一遍
- 使用清晰的变量名和注释
- 提前处理所有边界情况
测试用例
# Level 1 测试
storage = CloudStorage()
assert storage.add_file("file1.txt", 10) == True
assert storage.add_file("file1.txt", 20) == False
assert storage.copy_file("file1.txt", "file2.txt") == True
assert storage.get_file_size("file1.txt") == 10
# Level 2 测试
storage.add_file("music.mp3", 100)
storage.add_file("song.mp3", 50)
result = storage.find_file("", ".mp3")
assert len(result) == 2
# Level 3 测试
storage.add_user("alice", 100)
assert storage.add_file_by("alice", "doc.txt", 50) == 50
assert storage.add_file_by("alice", "image.jpg", 60) == None
# Level 4 测试
storage.compress_file("file1.txt")
assert storage.get_file_size("file1.txt") == 5
storage.decompress_file("file1.txt")
assert storage.get_file_size("file1.txt") == 10
总结
这道题从基础数据结构逐步升级到系统设计,考察的核心能力包括:
- 数据结构选择:哈希表、排序
- 状态管理:追踪文件、用户、容量
- 算法设计:搜索、排序、容量管理
- 代码质量:清晰的逻辑、完善的边界处理
关键要点:
- Level 1-2 是基础,必须全部通过
- Level 3 考察系统设计能力,是难点
- Level 4 是锦上添花,时间充足再做
🚀 需要面试辅助?
oavoservice 提供专业的 OA/VO 辅助服务,帮助你快速通过Meta、Amazon等大厂的技术面试。
👉 立即添加微信:Coding0201
我们的服务包括:
- 一对一模拟面试
- 实时代码审查
- 算法思路讲解
- 临场应对策略
联系方式
Email: [email protected] Telegram: @OAVOProxy