
題目概述
這是Meta的經典OA題目,考察對文件系統設計和數據結構的理解。整個題目分為4個難度等級,從基礎的文件操作逐步升級到複雜的用戶容量管理和文件壓縮。
時間分配建議:
- Level 1:15-20分鐘
- Level 2:20-25分鐘
- Level 3:25-30分鐘
- Level 4:15-20分鐘
Level 1:基礎文件操作
題目要求
實現一個內存雲存儲系統,支持三個基礎操作:
add_file(self, name: str, size: int) -> bool- 添加新文件到存儲系統。返回True如果添加成功,False如果文件已存在。copy_file(self, name_from: str, name_to: str) -> bool- 複製文件從name_from到name_to。如果源文件不存在或目標文件已存在,返回False。get_file_size(self, name: str) -> int | None- 返回文件大小,如果文件不存在返回None。
解題思路
這是最基礎的題目,直接使用**哈希表(字典)**存儲文件即可。
class CloudStorage:
def __init__(self):
self.files = {}
def add_file(self, name: str, size: int) -> bool:
if name in self.files:
return False
self.files[name] = size
return True
def copy_file(self, name_from: str, name_to: str) -> bool:
if name_from not in self.files or name_to in self.files:
return False
self.files[name_to] = self.files[name_from]
return True
def get_file_size(self, name: str) -> int | None:
return self.files.get(name)
時間複雜度分析
| 操作 | 時間複雜度 | 空間複雜度 |
|---|---|---|
add_file |
O(1) | O(1) |
copy_file |
O(1) | O(1) |
get_file_size |
O(1) | - |
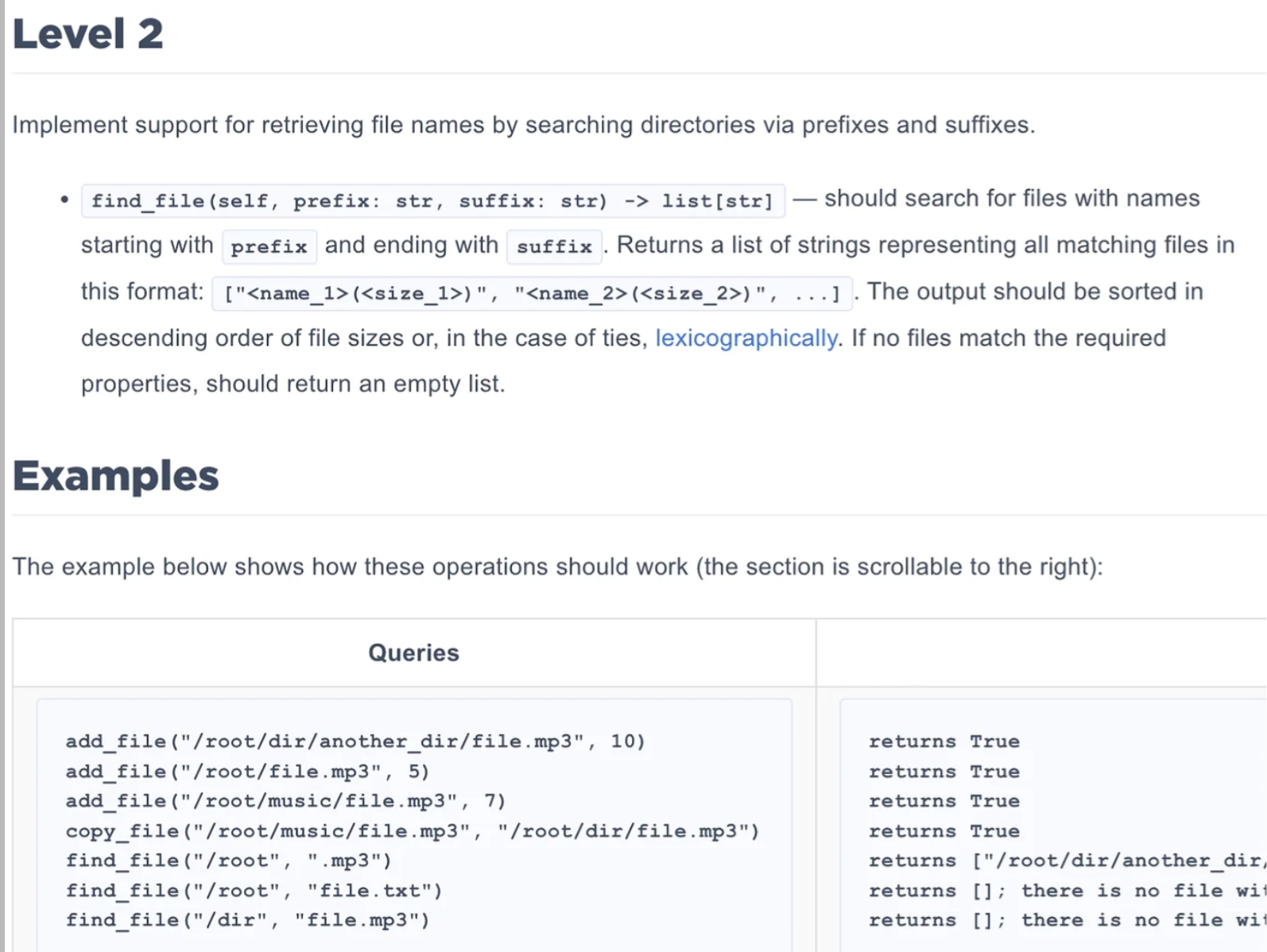
Level 2:前綴後綴搜索

題目要求
在Level 1的基礎上,添加文件搜索功能:
find_file(self, prefix: str, suffix: str) -> list[str]
- 搜索所有以
prefix開頭且以suffix結尾的文件 - 返回格式:
["<name_1>(<size_1>)", "<name_2>(<size_2>)", ...] - 按文件大小降序排列,相同大小按字典序排列
- 如果沒有匹配的文件,返回空列表
解題思路
關鍵是高效的字符串匹配和正確的排序。
def find_file(self, prefix: str, suffix: str) -> list[str]:
result = [
(name, self.files[name])
for name in self.files
if name.startswith(prefix) and name.endswith(suffix)
]
result.sort(key=lambda x: (-x[1], x[0]))
return [f"{name}({size})" for name, size in result]
時間複雜度分析
| 操作 | 時間複雜度 | 說明 |
|---|---|---|
| 搜索 | O(n·m) | n=文件數,m=平均名字長度 |
| 排序 | O(k·log k) | k=匹配的文件數 |
| 總體 | O(n·m + k·log k) | - |
Level 3:用戶容量管理

題目要求
支持多用戶和容量限制:
add_user(self, user_id: str, capacity: int) -> bool- 添加新用戶,分配存儲容量。用戶已存在返回False。add_file_by(self, user_id: str, name: str, size: int) -> int | None- 用戶添加文件,返回剩餘容量。如果超過容量限制,返回None。update_capacity(self, user_id: str, capacity: int) -> int | None- 更新用戶容量。如果新容量不足以容納現有文件,刪除最大的文件(字典序作為tiebreaker)。返回刪除的文件數。
解題思路
需要維護用戶-文件映射和容量追踪。
def add_user(self, user_id: str, capacity: int) -> bool:
if user_id in self.users:
return False
self.users[user_id] = capacity
self.user_files[user_id] = {}
return True
def add_file_by(self, user_id: str, name: str, size: int) -> int | None:
if user_id not in self.users:
return None
used = sum(self.user_files[user_id].values())
remaining = self.users[user_id] - used
if size > remaining:
return None
self.user_files[user_id][name] = size
self.files[name] = size
return remaining - size
def update_capacity(self, user_id: str, capacity: int) -> int | None:
if user_id not in self.users:
return None
self.users[user_id] = capacity
used = sum(self.user_files[user_id].values())
if used <= capacity:
return 0
files_list = sorted(
self.user_files[user_id].items(),
key=lambda x: (-x[1], x[0])
)
removed = 0
for name, size in files_list:
if used <= capacity:
break
del self.user_files[user_id][name]
del self.files[name]
used -= size
removed += 1
return removed
時間複雜度分析
| 操作 | 時間複雜度 |
|---|---|
add_user |
O(1) |
add_file_by |
O(1) |
update_capacity |
O(k·log k) |
Level 4:文件壓縮與解壓
題目要求
添加文件壓縮功能:
compress_file(self, name: str) -> bool- 壓縮文件,大小變為原來的一半(向下取整)。文件不存在返回False。decompress_file(self, name: str) -> bool- 解壓文件,恢復原始大小。文件不存在或未壓縮返回False。
解題思路
需要追踪文件的壓縮狀態和原始大小。
def compress_file(self, name: str) -> bool:
if name not in self.files or self.is_compressed[name]:
return False
self.files[name] //= 2
self.is_compressed[name] = True
return True
def decompress_file(self, name: str) -> bool:
if name not in self.files or not self.is_compressed[name]:
return False
self.files[name] = self.original_size[name]
self.is_compressed[name] = False
return True
完整代碼實現
class CloudStorage:
def __init__(self):
self.files = {}
self.original_size = {}
self.is_compressed = {}
self.users = {}
self.user_files = {}
def add_file(self, name: str, size: int) -> bool:
if name in self.files:
return False
self.files[name] = size
self.original_size[name] = size
self.is_compressed[name] = False
return True
def copy_file(self, name_from: str, name_to: str) -> bool:
if name_from not in self.files or name_to in self.files:
return False
self.files[name_to] = self.files[name_from]
self.original_size[name_to] = self.original_size[name_from]
self.is_compressed[name_to] = self.is_compressed[name_from]
return True
def get_file_size(self, name: str) -> int | None:
return self.files.get(name)
def find_file(self, prefix: str, suffix: str) -> list[str]:
result = [
(name, self.files[name])
for name in self.files
if name.startswith(prefix) and name.endswith(suffix)
]
result.sort(key=lambda x: (-x[1], x[0]))
return [f"{name}({size})" for name, size in result]
def add_user(self, user_id: str, capacity: int) -> bool:
if user_id in self.users:
return False
self.users[user_id] = capacity
self.user_files[user_id] = {}
return True
def add_file_by(self, user_id: str, name: str, size: int) -> int | None:
if user_id not in self.users:
return None
used = sum(self.user_files[user_id].values())
remaining = self.users[user_id] - used
if size > remaining:
return None
self.user_files[user_id][name] = size
self.files[name] = size
self.original_size[name] = size
self.is_compressed[name] = False
return remaining - size
def update_capacity(self, user_id: str, capacity: int) -> int | None:
if user_id not in self.users:
return None
self.users[user_id] = capacity
used = sum(self.user_files[user_id].values())
if used <= capacity:
return 0
files_list = sorted(
self.user_files[user_id].items(),
key=lambda x: (-self.files[x[0]], x[0])
)
removed = 0
for name, _ in files_list:
if used <= capacity:
break
used -= self.files[name]
del self.user_files[user_id][name]
del self.files[name]
removed += 1
return removed
def compress_file(self, name: str) -> bool:
if name not in self.files or self.is_compressed[name]:
return False
self.files[name] //= 2
self.is_compressed[name] = True
return True
def decompress_file(self, name: str) -> bool:
if name not in self.files or not self.is_compressed[name]:
return False
self.files[name] = self.original_size[name]
self.is_compressed[name] = False
return True
臨場應對策略
時間管理
| 階段 | 時間 | 任務 |
|---|---|---|
| 0-5分鐘 | 5分 | 理解題意,明確需求 |
| 5-25分鐘 | 20分 | 完成Level 1-2 |
| 25-55分鐘 | 30分 | 完成Level 3 |
| 55-85分鐘 | 30分 | 完成Level 4 + 測試 |
| 85-90分鐘 | 5分 | 檢查代碼,提交 |
常見錯誤
❌ 容量計算錯誤:忘記考慮壓縮狀態
❌ 排序順序混亂:大小降序 + 名字升序
❌ 文件所有權混淆:複製文件時保留原所有者
❌ 邊界條件遺漏:用戶不存在、文件不存在等
✅ 最佳實踐:
- 先完成基礎功能,再逐步添加複雜邏輯
- 每完成一個Level就測試一遍
- 使用清晰的變量名和註釋
- 提前處理所有邊界情況
總結
這道題從基礎數據結構逐步升級到系統設計,考察的核心能力包括:
- 數據結構選擇:哈希表、排序
- 狀態管理:追踪文件、用戶、容量
- 算法設計:搜索、排序、容量管理
- 代碼質量:清晰的邏輯、完善的邊界處理
關鍵要點:
- Level 1-2 是基礎,必須全部通過
- Level 3 考察系統設計能力,是難點
- Level 4 是錦上添花,時間充足再做
🚀 需要面試輔助?
oavoservice 提供專業的 OA/VO 輔助服務,幫助你快速通過Meta、Amazon等大廠的技術面試。
👉 立即添加微信:Coding0201
我們的服務包括:
- 一對一模擬面試
- 實時代碼審查
- 算法思路講解
- 臨場應對策略
联系方式
Email: [email protected] Telegram: @OAVOProxy